Pliki EJB-jar
Ostatnim etapem jest połączenie wszystkich elementów. Stworzone pliki zawierające interfejsy home i remote, klasę implementująca bean’a oraz deployment descriptor kompresujemy razem ręcznie lub przy pomocy jednego z wielu narzędzi do tworzenia archiwów jar, dostarczanych wraz z serwerem aplikacji. Tak przygotowane archiwum jest kompletnym komponentem EJB i może być instalowane i uruchamiane na każdym, zgodnym ze specyfikacją EJB, serwerze aplikacji.
Session Beans
Obecnie wyróżniamy trzy typy bean’ów: session bean’y reprezentujące procesy biznesowe, entity bean’y reprezentujące dane oraz message driven bean’y obsługujące wywołania asynchroniczne.
Bean’y typu session reprezentują obiekty i procesy o krótkim czasie życia (ang. transient). Może to być proces modyfikacji rekordów w bazie danych albo kopia dokumentu do edycji. Przede wszystkim są jednak specjalizowanymi obiektami biznesowymi dla indywidualnej obsługi klientów. Bean’y typu session potrafią zarządzać specyficzną dla konkretnego klienta informacją zawartą w jego sesji. Bardzo dobrym przykładem jest tu koszyk zakupowy, który jest obiektem dostępnym wyłącznie dla pojedynczego klienta. Informacja przez niego posiadana jest określana mianem „stanu konwersacji” (ang. conversational state), zawiera bowiem dopiero część danych jakie proces spodziewa się zdobyć dla przeprowadzenia akcji biznesowej. Bean’y typu session pamiętające stan swoich klientów w kolejnych wywołaniach nazywamy „stanowymi” (ang. statefull), a zorientowane na przetwarzanie pojedynczych odwołań „bezstanowymi” (ang. stateless). Obiekt sesyjny jest zwalniany w chwili gdy klient przestaje z niego korzystać. Wspomniany koszyk zakupowy jest obiektem tymczasowym każdego klienta, po złożeniu zamówienia nie jest już potrzebny i dlatego może być usunięty. W czasie procesu projektowego aplikacji wszystkie chwilowe obiekty zorientowane na obsługę pojedynczego klienta należy projektować jako potencjalne beany typu session.
Podkreślmy, że dzięki mechanizmom przełączania kontekstu udostępnianym przez kontener, jedna instancja bean’a typu session potrafi równolegle obsługiwać wielu różnych klientów. Może ona również pobierać informacje z bazy danych poprzez JDBC, a także potrafi obsługiwać transakcje.
Entity Beans
Entity beans są używane gównie do reprezentowania trwałych (ang. persistent) danych. Dane te są przechowywane w bazie danych lub dostępne poprzez zewnętrzną aplikację jako obiekt. Prostym przykładem jest reprezentowanie pojedynczego rekordu w tabeli bazy danych, każda instancja bean’a reprezentuje wtedy konkretny rekord. Bardziej złożonym będzie bean reprezentujący kilka połączonych tabel (ang. view), w którym każda instancja reprezentuje na przykład artykuł z koszyka klienta.
W przeciwieństwie do bean’ów typu session, bean’y typu entity są dostępne dla wielu klientów równocześnie. Synchronizowanie stanu konkretnej instancji poprzez stosowanie transakcji jest domeną kontenera. Programista nie musi więc martwić się o równoległy dostęp i tworzyć sekcji krytycznych przy dostępie do wybranych metod.
Persystentnością entity bean‘a może zarządzać sam bean lub też może ją zapewniać kontener. Przypadek kiedy bean sam implementuje metody zapewniające persystentność nazywamy Bean-Managed Persistance (BMP). Kiedy jest ona realizowana przez kontener mówimy o Container-Managed Persistance (CMP). W podejściu BMP programista musi implementować kod zapewniający synchronizację z bazą danych bezpośrednio w metodach bean’a wykorzystując interfejs JDBC. Może to pociągać za sobą problemy z przenośnością kodu bean’a między różnymi bazami danych, przede wszystkim jest jednak bardzo pracochłonne. Rozwiązania CMP zapewniają w sposób przeźroczysty zarządzanie jego persystentnością. Wszystkie zmiany wartości pól obiektu są automatycznie powielane w bazie danych. Programista nie tworzy kodu zapewniającego dostęp do bazy danych, co zapewnia pełną przenośność komponentu.
Message Driven Beans
Rozwiązywanie coraz bardziej złożonych problemów informatycznych prowadzi wcześniej lub później do konieczności wykorzystania modelu komunikacji asynchronicznej oraz przetwarzania kolejkowego. Mechanizmy umożliwiające ten proces są dostępne w języku Java jako JMS (ang. Java Messaging Service. Specyfikacja EJB 1.1 nie przewidywała integracji pomiędzy EJB a usługami JMS. Z tego powodu wysyłanie komunikatów do bean’a wymuszało aktywność bean przez cały czas w jakim miał on je obsługiwać, tak że zarządzanie jego cyklem życia z punktu widzenia kontenera było praktycznie niemożliwe. Dopiero specyfikacja EJB 2 .0 w pełni łączy obie technologie.
Message driven bean jest komponentem, który implementuje interfejs MessageListner, rejestruje się jako zainteresowany daną kolejką lub tematem, i oczekuje na przychodzące w sposób asynchroniczny komunikaty. Zachowuje się więc jak normalny klient JMS, przy czym jest w pełni kontrolowany przez kontener. Interakcja z klientem następuje zgodnie ze scenariuszem: Klient wysyła komunikat do serwera wiadomości (do odpowiedniej kolejki lub zgodnie z pewną tematyką). Następnie serwer wysyła wiadomość do message driven bean wywołując jego metodę onMessage(). Kiedy wiadomość nadejdzie, serwer aplikacji sprawdza czy żądany bean jest dostępny, jeśli takowy nie istnieje to tworzy jego instancję tak, by wiadomość została poprawnie przetworzona. Message driven bean działają zarówno w modelu wydawca-prenumerator jak i punkt-punkt są również dodatkowo wyposażone w mechanizmy transakcyjne.
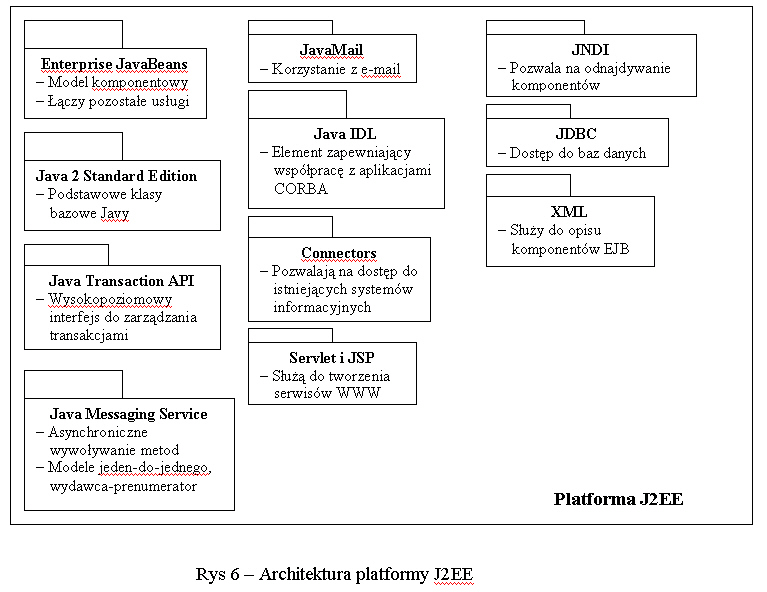
Platforma J2EE
Omówiony do tej pory model EJB jest sercem platformy J2EE. Pełną funkcjonalność uzyskujemy jednak dopiero dzięki wykorzystaniu szeregu usług, z których ten model korzysta.
JNDI
Jedną z podstawowych usług wykorzystywanych przez wiele systemów komputerowych jest usługa nazewnicza (ang. naming service) i katalogowa (ang. directory service). Głównym zadaniem usługi nazewniczej jest ułatwienie wyszukiwania obiektów, np. komponentów programowych, poprzez skojarzenie przyjaznych dla człowieka nazw z tymi obiektami. Dzięki istnieniu takiego skojarzenia można wyszukiwać obiekty posługując się nazwami właściwymi dla ludzi, a nie dla oprogramowania. Usługa katalogowa rozszerza z kolei usługę nazewniczą o możliwość posiadania przez te komponenty określonych atrybutów i pozwala m.in. na dodawanie, usuwanie i odczytywanie tych atrybutów. Daje więc możliwość nie tylko znalezienia odpowiedniego obiektu, ale także np. odczytania jego właściwości.
Potrzeba istnienia usługi nazewniczej zaowocowała powstaniem wielu różnorodnych standardów, takich jak np. OMG Naming i Trading Service czy LDAP (ang. Lightweight Directory Access Protocol). Każdy z nich precyzuje swój sposób zapisywania nazw, każdy może definiować inny protokół dostępu.
JNDI (ang. Java Naming and Directory Service) jest standardowym elementem języka Java, zawierającym zbiór interfejsów programistycznych, które pozwalają aplikacjom na korzystanie w sposób uniwersalny z już istniejących różnorodnych usług nazewniczych i katalogowych. JNDI umożliwia wyszukiwanie obiektów z wykorzystaniem usług katalogowych i nazewniczych bez świadomości jakie konkretne implementacje tych usług są wykorzystywane.
W przypadku EJB, JNDI jest używane przede wszystkim do wyszukania odpowiednich bean’ów EJB. Serwer aplikacji korzystając z JNDI wiąże określoną przez twórcę aplikacji nazwę do obiektu Java, a klient posiadając tę nazwę może używając JNDI wyszukać żądany obiekt, aby następnie np. móc wywoływać na nim odpowiednie operacje.
JDBC
Korzystanie w aplikacjach z bazy danych wymaga tworzenia zapytań w języku SQL (ang. Structured Query Language), wysyłania ich do systemu zarządzania bazą danych (DBMS — ang. Database Management System), odebrania odpowiedzi i jej zinterpretowania. Format zapytań SQL jest zależny od rodzaju wybranego DBMS (np. tekst jest czasami otaczany apostrofami, a czasami cudzysłowami), a więc tworząc aplikacje należy zawsze dostosowywać je do używanego typu DBMS.
JDBC (ang. Java DataBase Connectivity) jest standardowym elementem języka Java definiującym zbiór interfejsów i funkcji pozwalających aplikacjom na wykonywanie zapytań w języku SQL. Co ważne, JDBC uniezależnia programy od konkretnych baz danych takich jak Oracle czy Informix, oferując programiście jednakowy dostęp do wszystkich DBMS. Każdy z twórców bazy danych, która jest dostępna poprzez interfejs JDBC, dostarcza odpowiedni sterownik tłumaczący ujednolicone w JDBC wywołania funkcji na charakterystyczną dla tej bazy postać.
W modelu EJB za współpracę z bazą danych odpowiadają komponenty Entity Beans i to właśnie w nich przede wszystkim wykorzystywane jest JDBC. W przypadku CMP wywoływanie operacji JDBC wykonywane jest automatycznie przez kontener, który sam zapewnia synchronizację zawartości komponentów z bazą danych. Częstym zjawiskiem, i to zarówno w komponentach Entity jak i w Session Beans, jest korzystanie z JDBC bez pośrednictwa kontenera, ze względu na optymalizację. Konieczność optymalizacji w nawiązywaniu i zamykaniu połączeń z bazą danych przy korzystaniu z JDBC sprawiła, że serwery aplikacji udostępniają umieszczonym w nich aplikacjom pule połączeń. Ponieważ nawiązywanie i zamykanie połączenia są bardzo kosztownymi operacjami, to serwery zwykle przy uruchomieniu otwierają automatycznie określoną ilość (pulę) połączeń, tak by wszystkie umieszczone na nich aplikacje mogły współdzielić te połączenia bez potrzeby ich otwierania czy zamykania. W serwerze aplikacji za zarządzanie pulami połączeń oraz przydział połączeń poszczególnym bean’om odpowiada kontener. Pule połączeń, podobnie jak bean’y EJB, są wyszukiwane poprzez JNDI.
JTA
JTA (ang. Java Transaction API) jest standardowym elementem języka Java, który definiuje zbiór interfejsów i funkcji pozwalających aplikacjom na zarządzanie transakcjami. Użycie transakcji umożliwia zabezpieczanie integralności danych w bazach danych oraz zarządzanie dostępem dla aplikacji próbujących korzystać z danych jednocześnie. W przypadku rozpoczęcia transakcji, wszystkie operacje biorące w niej udział muszą się zakończyć sukcesem albo niepowodzeniem. Jeśli część operacji została zakończona sukcesem a choć jedna z pozostałych niepowodzeniem, to wszystkie poprzednie operacje muszą zostać odwołane.
W modelu EJB użycie transakcji nie jest ograniczone jedynie do dostępu do bazy danych. Może ono również obejmować wykonywanie operacji na bean’ach jak i np. przesyłanie komunikatów.
Specyfikacja EJB definiuje dwa sposoby zarządzania transakcjami: container-managed i bean-managed. W przypadku pierwszego sposobu, serwer aplikacji automatycznie administruje transakcjami. W drugim, cała odpowiedzialność za zarządzanie transakcjami spoczywa na barkach twórcy aplikacji, który używa JTA, aby rozpocząć, odwołać czy zatwierdzić transakcję.
JMS
Współpraca pomiędzy obiektami programowymi odbywa się zwykle poprzez wywoływanie metod obiektów kooperujących. Np. klient, chcąc, aby serwer wykonał operację, wywołuje odpowiednią funkcję serwera. Istnieje jednak, także inny rodzaj współpracy — poprzez wymianę komunikatów.
Komunikatem może być np. żądanie wykonania operacji czy też informacja o wystąpieniu określonego zdarzenia. Wzajemna interakcja za pomocą komunikatów różni się od standardowej interakcji za pomocą wywoływania operacji na obiektach tym, iż współpracujące ze sobą obiekty są słabiej sprzężone — nie porozumiewają się bezpośrednio tylko przez agenta, który ma możliwość otrzymywania i wysyłania komunikatów. Nadawca wysyła komunikaty do agenta, a odbiorca je od tego agenta otrzymuje. Nadawca komunikatu nie musi znać jego odbiorcy(ów) a odbiorca nadawcy. Wystarczy, aby obie strony komunikacji potrafiły komunikować się z agentem. Odbiorca może być nieaktywny lub jeszcze nie istnieć, w momencie gdy nadawca wysyła komunikat — w tym wypadku agent może przechować komunikat i dopiero w momencie aktywacji odbiorcy go przekazać.
JMS (ang. Java Messaging Service) jest standardowym elementem języka Java zawierającym zbiór interfejsów i funkcji, który umożliwia obiektom wzajemną współpracę poprzez wymianę komunikatów. JMS obsługuje dwa tryby obsługi wymiany komunikatów: punkt-punkt oraz wydawca-prenumerator. W pierwszym trybie, komunikat nadany przez jednego nadawcę jest odczytywany przez jednego odbiorcę, przy czym odbiorca sam musi się zatroszczyć o sprawdzanie u agenta dostępności komunikatów (tzw. pooling). W drugim trybie, komunikat nadany przez jednego nadawcę jest odczytywany przez wszystkich znanych agentowi odbiorców. Odbiorcy rejestrują się u agenta, a ten rozsyła do nich komunikaty automatycznie (tzw. callback).
W modelu EJB nadawcami komunikatów mogą być wszystkie komponenty aplikacji. Odbiorcami komunikatów pracującymi w trybie punkt-punkt mogą być również wszystkie elementy systemu, natomiast w trybie wydawca-prenumerator komunikaty odbierać mogą tylko message driven bean’y.
Java RMI
Java RMI (ang. Remote Method Invocation) jest standardowym elementem języka Java umożliwiającym wzajemną komunikację obiektów rozproszonych. RMI pozwala obiektowi, nazywanemu serwerem, udostępniać metody, które inny obiekt, zwany klientem, może wywoływać.
Architektura zdefiniowana przez RMI jest bardzo podobna do architektury CORBA: Twórca aplikacji będącej serwerem tworzy interfejs zawierający listę metod, które mogą być wywoływane przez klienta, a następnie tworzy obiekt implementujący ten interfejs. Za pomocą specjalnego kompilatora tworzy klasy odpowiedzialne za przekazywanie zdalnych wywołań od klienta do serwera.
Klient, chcąc wywołać metody na obiekcie serwera, musi go najpierw wyszukać — najprostszym sposobem jest użycie JNDI. Po wyszukaniu obiektu, klient wywołuje na nim funkcje w taki sam sposób jak na obiekcie lokalnym. Traktowanie serwera jako obiektu lokalnego jest możliwe dzięki stworzonym przez kompilator dwóm klasom zwanym stub i skeleton. Pierwsza z nich to reprezentant serwera, który znajduje się u klienta — to na nim klient wywołuje wszystkie metody. Stub konwertuje wywołania do postaci, którą można przesyłać przez sieć i wysyła ją do skeleton’a. Skeleton odczytuje jaka funkcja została wywołana oraz jakie są jej parametry i wywołuje ją na obiekcie serwera. Wynik wywołania funkcji skeleton przesyła z powrotem do stub’a, a ten przekazuje go do klienta. Dzięki istnieniu stub’a i skeleton’a istnienie sieci pomiędzy komunikującymi się klientem i obiektem serwera staje się dla nich przeźroczyste.
>XML
XML (ang. Extensible Markup Language) jest językiem opisu dokumentów tekstowych zbliżonym w składni do HTML-a. Różnica pomiędzy HTML-em a XML-em jest taka, że o ile pierwszy służy do tego aby określić jak dokument ma być prezentowany, o tyle drugi opisuje strukturę dokumentu nadając poszczególnym jego elementom odpowiednie znaczenie, przez co sprawiając, że dokumenty stają się samo-opisujące. Język XML jest obecnie bardzo dobrze znanym standardem, ma swoją ponad 3 letnią historię i jest akceptowany i używany przez wszystkie liczące się korporacje i ośrodki naukowe.
W architekturze EJB, XML został wykorzystany jako język służący do opisu komponentów programowych. Chcąc umieścić aplikację w kontenerze należy opisać środowisko, w którym aplikacja ma działać, podając np. zależności pomiędzy klasami języka Java, sposób odwzorowania Entity Bean na tabele w relacyjnych bazach danych, uprawnienia definiujące kto ma prawo do wykonywania określonych funkcji itp. Cała ta informacja jest zapisana właśnie z wykorzystaniem języka XML.
Bibliografia
[1] http://java.sun.com/j2ee
[2] Prashant Sridharn – “Java Beans –
developer’s resources”, Prentice Hall PTR
[3] Jim Melton – “Understending the
new SQL: a complete guide”, Morgan Kaufman Publishers,
1993
[4] Rahim Adatia, Faiz Arni i inni –
“Professional EJB”, Wiley Computer Publishing, 1999
[5] Ed Roman – “Mastering Enterprise
JavaBeans and the Java 2 Enterprise Edition”,
Wrox Press Ltd,
2001
[6] Richard Monson-Haefel –
“Enterprise Java Bean”, O’Reilly, 1999
[7] Robert Orfali, Dan Harkey – “Java
and Corba”, John Wiley&Sons Inc., 1997
[8] Sun Microsystems – “Core
Java”, Sun Microsystems Press 1999
[9] Scott Oaks – “Java Security”,
O’Reilly, 1999
Autorzy
Dominik Radziszowski i Paweł Rzepa są pracownikami Grupy Systemów Rozproszonych Katedry Informatyki AGH. Swoje działania skupiają obecnie na tworzeniu i adaptacji komponentów EJB dla potrzeb telemedycyny i telediagnostyki, ze szczególnym uwzględnieniem bezprzewodowego dostępu z różnych platform sprzętowych (PC, PDA, telefon) oraz realizacji transmisji multimedialnych w oparciu o te platformy.